我们在编写复杂的C/C++程序时,会将代码拆分到多个源文件中。这么做有很多好处:
- 便于组织和管理代码;
- 便于在不同的程序(项目)之间共用代码和利用已有的代码
- 减少程序修改后编译的工作量,提高编译速度
小熊猫C++提供了项目功能,可以对多文件程序进行管理、编译运行和调试。
我们在编写复杂的C/C++程序时,会将代码拆分到多个源文件中。这么做有很多好处:
小熊猫C++提供了项目功能,可以对多文件程序进行管理、编译运行和调试。
计算机并不能直接执行C或者C++语言指令,因此C/C++程序必须被翻译(translate)成计算机(CPU)认识的指令(机器语言指令),并按照特定的格式保存在可执行文件(Executable)中之后,才能被计算机载入执行。在C++11(ISO/IEC 14882:2011)标准中,将从C/C++源程序文件到可执行文件的过程称为"translation"。在很多C/C++教材中,也将这个过程称为**“Compilation”(编译)**。
由于compilation/compile在不同的情境下有不同的含义,为了便于的区分,很多工具软件将这个过程称为build(构建)。
下图展示了C/C++编译(构建)程序的一般过程:
graph TD
subgraph 构建
Source1{{源文件}} -- 预处理 --> TranslationUnit1[编译单元]
Header1[[头文件]] -.-> TranslationUnit1[编译单元]
Source2{{源文件}} -- 预处理 --> TranslationUnit2[编译单元]
Header2[[头文件]] -.-> TranslationUnit2[编译单元]
Source3{{源文件}} -- 预处理 --> TranslationUnit3[编译单元]
Header3[[头文件]] -.-> TranslationUnit3[编译单元]
TranslationUnit1 -- 编译 --> TranslatedUnit1([目标文件])
TranslationUnit2 -- 编译 --> TranslatedUnit2([目标文件])
TranslationUnit3 -- 编译 --> TranslatedUnit3([目标文件])
end
subgraph 链接
TranslatedUnit1 & TranslatedUnit2 & TranslatedUnit3 -- 链接 --> Executable[/可执行文件/]
end
编译的第一步是对源文件(source file)进行预处理(preprocess)。预处理包括转码、标记切分(tokenize)、宏替换等很多工作,但其中最重要的工作是把源文件中#include语句包含的头文件(header)的内容和源文件合并在一起成为一个整体,也就是所谓的"编译单元"(translation unit)。
每一个源文件经过预处理后都会得到一个"编译单元"。
在gcc编译时加入"-E"参数,就可以将源文件预处理后得到的编译单元保存到指定的文件中。
编译过程的下一步是将编译单元转换为机器代码,这个步骤一般叫做"编译"(compilation),编译得到的机器代码被称为"translated unit"(“被编译单元”)。 当被编译单元保存到文件中时,我们会将该文件称为"目标文件"(object file),通常以.o或者.obj作为目标文件的后缀名。
因为"被翻译单元"这个说法在中文中比较别扭,所以我们一般用"目标文件"来代替它,即使"目标文件"并没有被实际存到文件里。
说明:很不幸,编译这个词被在不同的地方表示了不同的含义。不过根据上下文,我们一般都能够理解"编译"到底是指从源文件到目标文件,还是从编译单元到目标文件。
链接是整个编译过程中的最后一步,将一个或者多个目标文件整合成一个可执行文件。这是多文件编译时最容易出问题的步骤。
下图是一个典型的链接错误提示(首先,错误提示显示的文件名是个目标文件"xxxx.o";其次,ld(gcc的链接程序)程序错误退出"ld returned 1 exit status"):
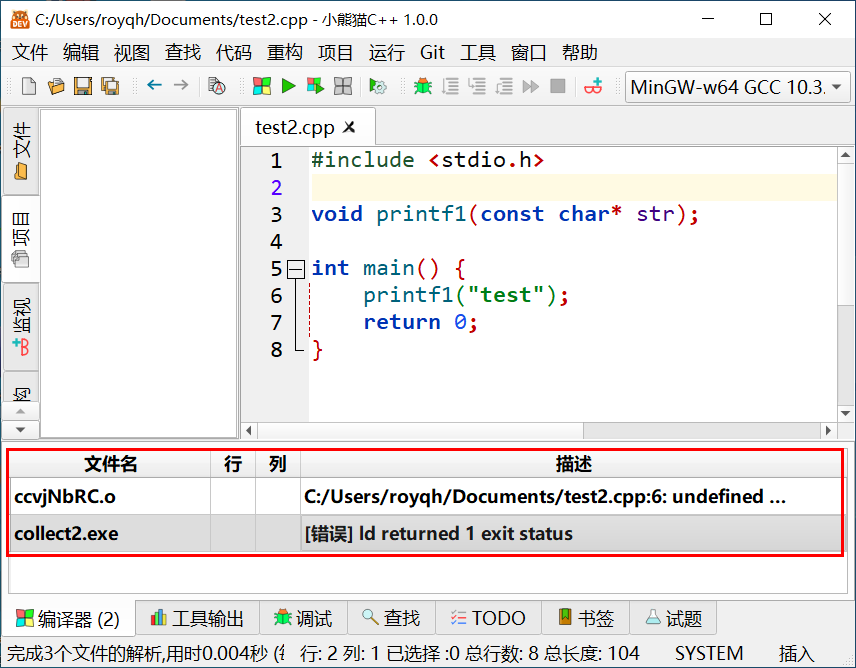
常见的错误问题有:
在链接时我们可能会需要用到.a或者.lib结尾的库文件(library file),这些文件实际上是由多个预先生成的目标文件组成的包。链接某个库文件实际上就是链接包里面的目标文件。
在gcc编译时,指定-lxxx参数,实际是让gcc链接libxxx.a库文件。
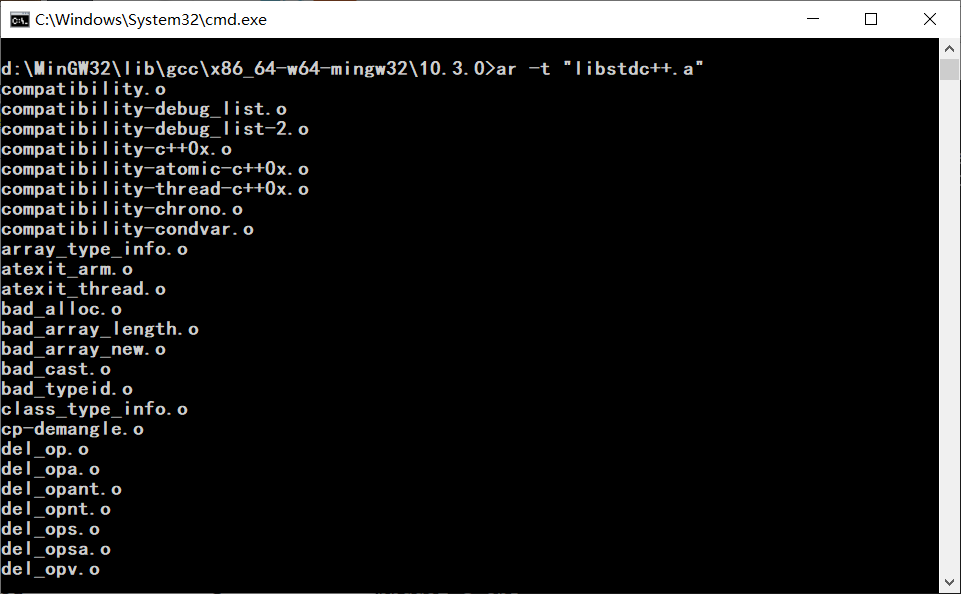
使用gcc工具集里的ar命令可以管理和查看.a文件中的内容。下图显示了libstdc++.a库文件中包含的目标文件:
在编译C/C++程序时,缺省gcc会自动链接标准库的库文件。因此,我们不需要告诉gcc怎么找到printf等标准库函数的定义,gcc就能够正确编译和链接普通的程序。
gcc一次运行只能进行单个文件的编译,单个文件的编译链接,或者多个文件的链接;无法完成多个文件的编译和链接。因此,需要按照一定的顺序多次运行gcc,才能完成一次完整的多文件编译链接。
此外,我们在维护和修改维护软件时,往往需要在只更新了一两个源文件的情况下重新生成可执行文件。显然,此时只需要对那些修改过的源文件重新编译得到更新的目标文件;没有修改过的源文件没有必要重新编译一遍。
为了方便这个过程,大家使用make工具来管理和执行这个过程。它的核心功能就是检查相关的源文件和头文件和对应的目标文件相比是否有更新,重新编译那些受到变化影响的源文件得到更新的目标文件,然后重新链接所有的目标文件最终得到新的可执行文件。
一般我们会用一个配置文件用来告诉make工具,生成可执行性文件需要哪些目标文件,每个目标文件又对应哪个源文件以及涉及哪些头文件,应该如何编译等等信息。这个配置文件被称为makefile,一般使用Makefile或者Makefile.win作为它的文件名。
小熊猫C++在编译单文件时,会直接调用gcc;在多文件编译(编译项目)时,会根据项目信息,自动生成makefile,然后调用make程序来完成编译。
下面是小熊猫C++自动生成的一个项目makefile:
# Project: 项目23
# Makefile created by Red Panda C++ 1.0.0
CPP = g++.exe
CC = gcc.exe
WINDRES = windres.exe
RES = 项目23_private.res
OBJ = main.o glmatrix.o $(RES)
LINKOBJ = main.o glmatrix.o $(RES)
CLEANOBJ = main.o glmatrix.o $(RES)
LIBS = -lwinmm -mwindows -lm -lfreeglut.dll -lopengl32 -lwinmm -lgdi32
INCS =
CXXINCS =
BIN = 项目23.exe
CXXFLAGS = $(CXXINCS) -Wall -Wextra -g3 -pipe -D__DEBUG__
CFLAGS = $(INCS) -Wall -Wextra -g3 -pipe -D__DEBUG__
RM = del /q /f
.PHONY: all all-before all-after clean clean-custom
all: all-before $(BIN) all-after
clean: clean-custom
${RM} $(CLEANOBJ) $(BIN) > NUL 2>&1
$(BIN): $(OBJ)
$(CPP) $(LINKOBJ) -o $(BIN) $(LIBS)
main.o: main.c glmatrix.h
$(CPP) -c C:/Users/royqh/Documents/projects/项目23/main.c -o main.o $(CXXFLAGS)
glmatrix.o: glmatrix.c glmatrix.h
$(CPP) -c C:/Users/royqh/Documents/projects/项目23/glmatrix.c -o glmatrix.o $(CXXFLAGS)
项目23_private.res: 项目23_private.rc
$(WINDRES) -i 项目23_private.rc --input-format=rc -o 项目23_private.res -O coff
从中我们可以看到,"$(BIN)"(也就是"项目23.exe")依赖于"$(OBJ)"(main.o、glmatrix.o等目标文件);而main.o依赖于main.c和glmatrix.h。make程序会根据这些信息来自动判断应该执行哪些操作来生成项目23.exe文件。
通过"文件"菜单→“新建”→“新建项目…",可以打开新建项目对话框。